
Predictive Coding for eDiscovery

What is Predictive Coding?
In eDiscovery, predictive coding is a way to automate the document review process by leveraging machine learning algorithms. While there are different types of predictive algorithms, most predictive coding tools surface relevant documents based upon previous review decisions or classify documents according to how they match concepts in sample documents.
This typically works by taking information gained from manual coding and automating that logic to a larger group of documents. Reviewers use a set of documents to identify potentially responsive documents and then train the computer to identify similar ones. Technology is used to predict how certain documents would be coded, based on how they were coded manually.
Hence, the name predictive coding.
But how do you know if your system’s predictions are accurate? To guide the process and measure effectiveness, these processes generally incorporate statistical models and/or sampling techniques alongside human review.
What Is Predictive Coding? Predictive Coding Vs. Technology-Assisted Review
To avoid confusion, it is important to note that not all technology-assisted review, or TAR (Technology Assisted Review), involves predictive coding, although the terms are sometimes used interchangeably.
Predictive coding is just one form of TAR, which is itself a broader category that encompasses many uses of technology in the document review process. It is also important to note that predictive coding does not replace culling or early case assessment in the review process. For example, some TAR methods, like culling irrelevant data from a document collection, are used before applying predictive coding technology.
How Does Technology-Assisted Review Work?
Although there are different examples of technology-assisted review in action, a traditional and defensible document review process that applies predictive coding techniques looks like this:
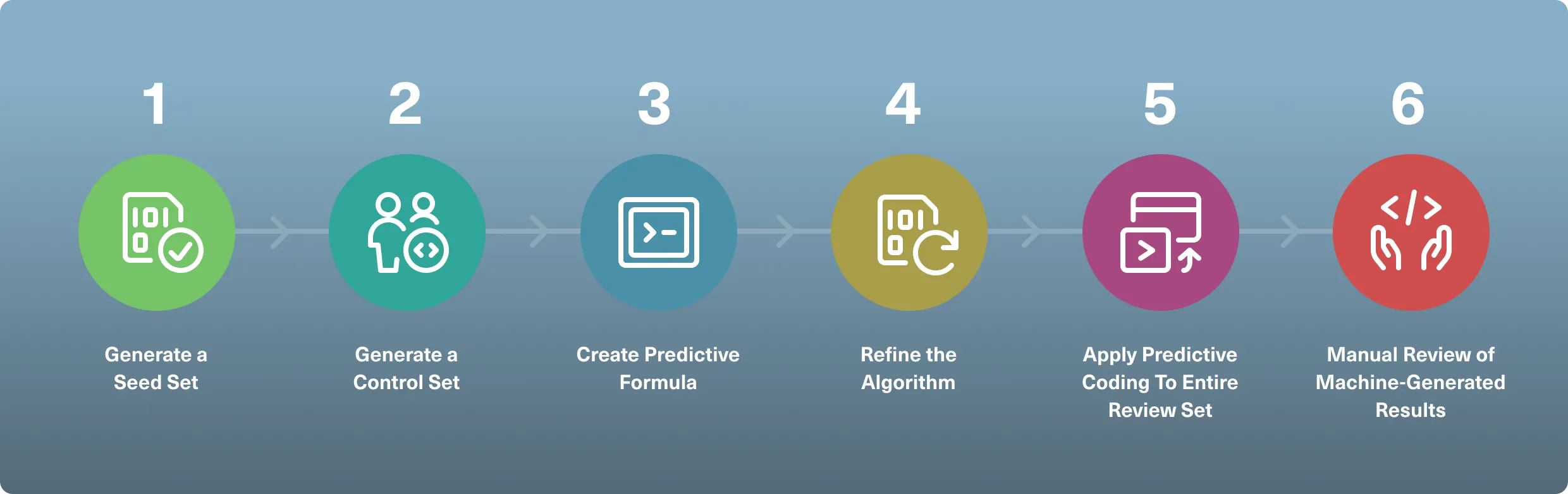
- Generate a Seed set: After the initial culling of data, most predictive coding workflows start by selecting and coding a sample from the review set, called the seed set. These documents are labeled by one or more subject matter experts as relevant or non-relevant, from which a machine learning algorithm then infers how to distinguish future documents.
- Generate a Control Set: This is random sample of documents coded by human reviewers at the start of a search or review process that is separate from and independent of the training set. Control sets are used to measure the effectiveness of the machine learning algorithm.
- Create Predictive Formula: After the predictive coding software analyzes the seed set, it generates an internal algorithm for predicting the responsiveness of future documents.
- Refine the Algorithm: As with the manual review process, predictive coding workflows are iterative. The iterative process involves repeatedly updating the training set with additional examples of coded documents to refine the algorithm and improve results. In some systems, machine learning allows getting the algorithm automatically updated based on reviewer decisions.
- Apply Predictive Coding To Entire Review Set: Have your predictive software apply the algorithm to the entire review set to get the most relevant documents automatically surfaced for you.
- Manual Review of Machine-Generated Results: It is critical to have a lawyer review all documents coded by the machine to verify quality. Attorneys should continually review the results and refine their search methods in order to train the system.
It’s important to note that the newest forms of TAR use continuous active learning, which makes the seed set unnecessary. Rather, human reviewers simply begin coding documents while the computer observes in the background, learning from their behavior and decisions. Based on these decisions, the system will start providing tag suggestions, which will get more and more accurate as reliable human reviewers continue feeding the algorithm with information.
The Benefits of Using AI in eDiscovery
Back in the day, using machine learning in eDiscovery was not an easy or affordable task.
For one, the technology behind predictive coding was too complex, which required experts in statistical sampling to operate the software. Hiring those professionals was difficult and costly, let alone the software itself and associated expenses (implementation, training, etc.)
But nowadays, there are much simpler tools that anyone can use to apply AI to legal document review. For example, Logikcull’s built-in AI, Suggested Tags, learns from your tagging decisions and offers tag suggestions that you can use to find the “smoking gun” much faster.
Today’s more user- and cost-friendly ways to incorporate machine learning into the eDiscovery process can be extremely useful. They can save you thousands of hours and dollars in review time by helping you prioritize your review set and find the most responsive records faster than ever before.
Paired with Culling Intelligence to quickly get any irrelevant documents out of the way, new predictive coding tools can make your eDiscovery process much more efficient and inexpensive as you can develop the bandwidth to handle it in-house.
Concerns About Predictive Coding
There are a few challenges associated with using machine learning in eDiscovery that have many practitioners still wondering, “Does predictive coding have a future?”
Some of the most common concerns around predictive coding are:
Opacity
Because predictive coding relies on highly complex algorithms to determine responsiveness, rather than individual human judgment, some critics describe it as a “black box.” That is, the information goes in and information comes out, but the internal processes are opaque. How the technology works, and thus how coding decisions are made, has been traditionally understood by only a few experts—and very few of them are lawyers.
Defensibility in Court
Although most judges consider predictive coding as a standard and accepted practice in eDiscovery, there is still debate about the level of scrutiny courts should apply to TAR claims. Magistrate Judge David J. Waxse, for example, has argued that courts must act as gatekeepers when evaluating the appropriateness of TAR. Evidence about TAR’s capabilities would have to meet the standards established in the Supreme Court’s Daubert v. Merrell Dow Pharmaceuticals decision and Federal Rule of Evidence 702. On the other hand, Magistrate Judge Andrew J. Peck has said that those standards are “not applicable to how documents are searched for and found in discovery.”
Software Sophistication
As mentioned earlier, the fact that, until recently, technology-assisted review software could only be operated by technical experts has been a major concern for legal teams, which usually don’t have the time and resources to bring this kind of technology in-house. Recently developed user-friendly AI-powered discovery tools are lowering the resistance (and costs) of adopting this powerful technology to speed document review.
Checklist: Predictive Coding Best Practices
Download a printable version of the predictive coding best practices checklist
Technology-Assisted Review Software
When it comes to choosing the right TAR eDiscovery software for your legal team, it's important to remember that there are two main approaches to technology-assisted review:
- Predictive coding: The most traditional type of eDiscovery AI, predictive coding involves loading a “seed set” to the system to train the predictive algorithm. The quality of the results will depend on the quality of this original seed set, which can only be altered by adding subsequent sample sets with updated coding to retrain the machine.
- Continuous active learning: Developed more recently, this TAR doesn’t need a seed set. The algorithm automatically learns from the reviewers' decisions and starts feeding the review team what it determines are the most important documents. The system gets smarter and smarter as it keeps receiving input from human reviewers.
Because of its simplicity and increasingly accurate results, the latter is usually the choice for innovative legal teams that want to keep control over their review process rather than outsourcing it to expert vendors. With modern AI eDiscovery software such as Logikcull’s Suggested Tags, you can do things like:
- Get tag suggestions based on how you applied the same tag previously, including the percentage of confidence in tag accuracy
- Apply Suggested Tags in bulk
- Have smarter and more accurate suggestions over time
- Use it without any previous training
Powerfully simple TAR software that does most of the heavy lifting for you without any prior training can be a game-changer for the speed and efficiency of your discovery process.
Predictive Coding Terminology
TAR involves complex algorithms, based on sophisticated mathematical and linguistic models. As in the law, the expert lingo can seem impenetrable to outsiders.
Here are some of the common concepts and terms you might need to know to navigate this world:
Algorithm: A specified set of computations used to accomplish a particular goal. The algorithms used in eDiscovery are implemented through computer software.
Artificial Intelligence: A general term for computer programs that are designed to simulate human judgment. Artificial intelligence includes machine learning, which allows computers to change when exposed to new data, without needing manual programing.
Boolean Search: A search methodology that uses keywords to pull results through using connecting words like “and” or “or” to find specific combinations. In more complex litigation, more sophisticated Boolean strings are often used with a fuzzy search technique, designed to account for variations in spelling and word choice.
Concept and Categorization Tool Search Systems: These techniques rely on a thesaurus to capture documents that use different words to express the same thought.
Clustering: A grouping method in which documents are organized into categories so that those in one category are more similar to each other than to those in another category. Clustering is an automated process and the categories made may or may not be valuable for review.
Fuzzy Search Models: A method to refine a search beyond specific words, recognizing that words can have multiple forms. In fuzzy search models, even if search terms don’t use the exact words in a relevant document, the document might still be found.
Natural Language Search: A non-Boolean search method, whereby search commands are input as one would speak naturally. This is the type of search associated with search engines like Bing and Google.
Probabilistic Search: Search based on language models, including Bayesian belief networks, which make inferences about the relevance of documents based on how concepts are communicated in a collection.
Subjective Coding: The classification of documents based on a subjective judgement about their responsiveness, privilege, or other categories.
Case Law and Examples Around Predictive Coding
The first court case to embrace predictive coding as an allowable review strategy was 2012 Da Silva Moore v. Publicis Groupe. U.S. Magistrate Judge Andrew Peck of the Southern District of New York wrote at the time, “What the bar should take away from this opinion is that computer-assisted review is an available tool and should be seriously considered for use in large-data-volume cases where it may save the producing party (or both parties) significant amounts of legal fees in document review. Counsel no longer have to worry about being the ‘first’ or ‘guinea pig’ for judicial acceptance of computer-assisted review.”
In the years since, a handful of subsequent opinions have continued to address the issue. Here are some of the most notable:
In re Actos (Pioglitazone) Products Liability Litigation, MDL No. 6:11-md-2299 (W.D. La. July 27, 2012).
This product liability action included a case management order allowing the parties to use a “search methodology proof of concept to evaluate the potential utility of advanced analytics as a document identification mechanism for the review and production” of ESI. The search protocol provided for the use of a TAR tool on the emails of four key custodians.
Global Aerospace, Inc. v. Landow Aviation, L.P., No. CL 61040 (Vir. Cir. Ct. Apr. 23, 2012).
Virginia Circuit Court Judge James H. Chamblin ruled that the defendants may use predictive coding for the purposes of processing and producing ESI.
Nat’l Day Laborer Org. Network v. U.S. Immigration & Customs Enforcement Agency, 2012 WL 2878130 (S.D.N.Y. July 13, 2012).
U.S. District Court Judge Shira Scheindlin held that the federal government’s searches for responsive documents, requested pursuant to FOIA, were inadequate because of the government’s failure to properly employ modern search technologies. Judge Scheindlin urged the government to “learn to use twenty-first-century technologies,” including predictive coding as opposed to simple keyword search.
In re Biomet M2a Magnum Hip Implant Prods. Liab. Litig., 2013 U.S. Dist. LEXIS 172570 (N.D. Ind. Aug. 21, 2013).
U.S. District Court Judge Robert L. Miller Jr. ruled that the defendants need not identify which of the documents, from among those they had already produced, were used in the training of the defendants’ TAR algorithm. However, the court said that it was troubled by the defendants’ lack of cooperation.
Hyles v. NYC, No. 110-cv-03119 (S.D.N.Y. Aug. 1, 2016)
In this case, Judge Peck again addressed TAR, ruling that plaintiffs could not force the producing party to use TAR in its review. “It certainly is fair to say that I am a judicial advocate for the use of TAR in appropriate cases,” Judge Peck wrote, but he found no reason to compel its use in this case. “Responding parties are best situated to evaluate the procedures, methodologies, and technologies appropriate for preserving and producing their own electronically stored information.”
In re Mercedes-Benz Emissions Litigation, No.: 2:16-cv-881 (KM) (ESK) (D.N.J. Jan. 8, 2020).
In this litigation, Plaintiffs requested the Court to compel Defendants to use TAR rather than search terms to identify potentially responsive documents. Defendants argued the use of TAR was not appropriate due to “unique issues” that would adversely affect “an appropriate and effective seed set.” Although Judge Cavanaugh denied the motion to compel, recognizing the responding party is in the best position to determine its own responsiveness methodology, he noted it would “not look favorably on any future arguments related to burden of discovery requests, specifically cost and proportionality” due to the “wide acceptance that TAR is cheaper, more efficient and superior to keyword searching.”

The Ultimate Guide to eDiscovery
Want to see it in action? Request a demo today
Our team of product specialists will show you how to make Logikcull work for your specific needs and help you save thousands in discovery.