
The Lawyer’s Guide to Discovery and Investigations in Slack
Everything you always wanted to know about Slack discovery but were afraid to ask.

Summary: What is Slack data?
Slack is, in essence, a data repository fused with a high-tech chat room—and it's changing the way we communicate.
- Slack has over 12 million daily users, users from the smallest organizations to more than 65 percent of Fortune 100 companies.
- Companies that use Slack have seen a dramatic drop in email usage, by 49% according to one study.
- Slack can make discovery incredibly difficult if you don't have the policies and tools in place to deal with Slack data.

A “team collaboration tool” that allows users to message, share files, search conversations, archive information and more, Slack is, in essence, a data repository fused with a high-tech chat room. Slack allows fast paced communication, all logged in a highly searchable environment called a “workspace.”
Thanks to Slack, more and more business communication is moving from the inbox to the chat room. One of the fastest growing apps ever, Slack is used by everyone from the smallest startups to Fortune 100 companies—more than 65 percent of them. It has more than twelve million of daily users, sending more than 1.5 billion messages per month, across thousands of organizations.
This is Slack: The Face of Communications Today?
.webp)
Slack is Disrupting Discovery and Investigations
Slack represents an incredible challenge for modern legal professionals. In the past, legal teams only had to sift through emails, Office documents, PDFs, and images. When it comes to litigation and investigations, existing systems are designed for these processes, for discrete documents.
Legal teams are used to documents. Not chat rooms.
But chat rooms are taking over. In one survey, nearly 20 percent of companies who adopted Slack saw their email use decline by 40 to 60 percent. Today, if you’re only dealing with emails, you’re missing half the story.
Slack makes discovery for legal teams incredibly painful. With Slack, users can direct message, create chat rooms, share files, edit—or, depending on the context, spoliate—Slack messages from the past, and more. Account managers may not have access to certain Slack communications. Through thousands of integrations, Slack gathers a massive amount of data, all stored in one place. Further, individual users can even set their own retention and deletion policies, greatly complicating attempts at consistent information governance.
But beyond that, how do you even review Slack data when, until recently, virtually no discovery platform was capable of handling it?
.webp)
Difficult Data—and Tons of It
Slack stores an enormous amount of data. By default, Slack preserves all messages forever, creating a mammoth archive of an organization’s communications.
That data is not limited to messages sent between Slack users. Slack amalgamates data from hundreds of sources, all in one place. With more than 1,000 connected apps, Slack has created a centralized hub of information that can pull together a massive universe of information.
.webp)
Data in Slack is paradoxical: It is both disjointed, highly connected to other data sources, and constantly variable, all at once.
Communication in Slack may take place in public channels, similar to open chat rooms. It may happen in private, where only the participants know what is being communicated. Or it may happen one-to-one, through direct messages.
And those records are editable—all of them. Users can create and delete channels, edit individual messages, add and remove files, create, modify, or remove integrations, and get rid of visible records altogether.
To properly handle Slack data in litigation and investigations, legal teams need to understand Slack itself—and the unique data, preservation, and interpretation challenges Slack presents...
Slack 101: Understanding Slack for Lawyers and Legal Professionals
Summary: How Slack is Impacting Discovery
Slack’s viral growth is largely due to the way it gathers information into one, centralized hub.
- Slack is organized into "workspaces," with communication taking place in channels, both public and private, and
- With thousands of integrations, users can create files, update databases, hire and fire employees, seek legal counsel and much more, all through Slack.
- Slack records are incredibly rich, recording a wealth of data, including user edits, interactions, and more.
Slack bills itself as an “email killer” and “where work happens.” In some organizations, this is almost true. In a 2015, 1,629 paid users reported that Slack reduced their organization’s email usage by an average of 48.6 percent.
In some organizations, Slack simply supplements existing communications channels, perhaps reducing email use slightly while greatly increasing the messages sent directly through chat. In many others, Slack may exist as “shadow IT,” technology that is used without official sanction.
And it’s incredibly popular. Slack’s success has made it the fastest growing SaaS company ever and allowed it to make its way into more than 65 percent of the Fortune 100 companies.
Slack’s viral growth is largely due to the way it gathers information into one centralized hub. Slack lets teams bring all their communication and much of their work into one place, allowing them to compose messages, share files, integrate information from third-party apps, and even make phone calls, all without ever leaving Slack.
Communication in Slack: Workspaces, Channels, Direct Messages, and more
49% reduction in email after introducing Slack
Workspaces: a central "hub" for communications
Channels: chat rooms may be public or private
Direct Messages: private messaging between users
Guests: guests may have limited access to workspaces
Slack organizes communication through “workspaces.” This is the digital space where a team shares communication and files. Companies may have a single workspace, such as acme.slack.com, for the entire organization, or they may have several workspaces organized around function, location, project, etc. These workspaces can be wholly independent of each other or connected through the Slack Enterprise Grid.
Workspaces consist of persistent chat rooms called “channels.” These channels can be both public and private. Public channels are open to any team member in the workspace, meaning that almost anyone can join them, view conversations, and search for past content. There is one exception to the open nature of public channels, though: guests. Guests are members of a Slack workspace who do not have full access to public channels. A guest may be a contractor, temp, or third party who is invited in to a workspace for a limited purpose. To join a channel, even a public one, they must be invited in by a workspace member.
.webp)
In addition to public channels, workspaces can contain private channels, which cannot be seen by other members. Private channels are considered “confidential.” Members must be invited into a private channel to participate in the conversation or to search its contents.
By default, any team member can create new public and private channels. Slack further allows private communication through direct messages, which can involve as few as two participants and as many as nine. Like private channels, these conversations are limited to invited members.
Making Sense of Slack's Idiosyncrasies
In addition to where communication happens in Slack, the platform also introduces some idiosyncrasies to how communication happens. First, Slack lets individual users “star” messages, channels, and files. A star is meant to mark an item as important. Only individual users can see their starred items in Slack.
Users can also “pin” items, marking it for greater attention. Other members in a channel or conversation will be informed that an item was pinned, and that pin item is then incorporated into the conversation details pane. Users can also “react” to items in Slack. Reactions allow users to respond to a message with an emoji, whether a heart, a smile, or two clinking beer glasses.
If starring an item is relatively straightforward, reacting to one is not, introducing a host of interpretative problems that we discuss in the chapters that follow.
.webp)
Finally, Slack is a “platform agnostic” product, making communication even more seamless. Because Slack is cloud-based, it can be accessed from virtually any device and platform. Slack works in web browsers, as a desktop app, on mobile devices and even Apple Watch, allowing users to communicate no matter where they are or what device they are using. This, in turn, helps feed the 24/7 discussions that can make Slack so valuable in discovery and investigations.
Apps and Integrations in Slack
Slack includes hundreds of integrations with other tools, turning the Slack platform into a centralized repository of information. Google Drive integrations, for example, can create a Slack message every time a new document is created, access to a file is requested, or a spreadsheet updated.
Slack’s app directory lists dozens of apps broken down by categories such as file management, finance, project management, security and compliance, and more. The Time Doctor app, for example, tracks user activities and provides statistics on “where time was spent such as viewing websites and applications used when working.” The Stripe app sends messages when charges are made, invoices updated, transfers sent and more. The Spectr app offers real-time legal advice, delivered directly in Slack, from a “professional legal advisor.”
.webp)
With an addicting interface, always-on platform, and thousands of integrations Slack can quickly become a central hub for information and communication. And getting data into Slack is easy.
But, when it comes to discovery and investigations, how do you get it out?
Preserving, Collecting and Exporting Slack Data for Discovery
Summary: Exporting Slack Data for Review
As Slack data increasingly supplements, and occasionally supplants, email as a primary form of business communication, preserving, collecting, and reviewing Slack data is essential for a complete discovery or investigation process.
- Slack's default retention setting is to retain everything, forever, but retention schedules may be adjusted by administrators or individual members themselves.
- Slack allows users to edit and delete messages, but keeps a record of these changes.
- Retention and export options vary be Slack account type.
- Depending on your Slack plan, you may not have easy access to data from private channels and direct messages.
There Are Four Key Features of Data in Slack:
- It is immense
- It is shifting
- It is not easily accessible
- It is not easy to interpret

Data Retention in Slack
Slack can quickly generate vast amounts of data. There are, first and foremost, the millions of messages that can be exchanged in a workspace in one day. Then there is the associated metadata, the timestamps, channel information, edit logs and the like.
But Slack is more than chat. Through apps and integrations, information can be pulled from outside sources in to Slack. Documents, from the most complex database file to a funny photo, can also be directly uploaded and shared through the platform, adding even more information to the stockpile.
By default, that data is stored forever. But, Slack allows workspace owners to customize their message and file retention policies. Files may be kept for the lifetime of the workspace or deleted after a specified time period.
Slack Retention Settings
Ability to move from collection to review in minutes
Slack Retention Settings
Retain everything, forever
Retain all messages but not revisions
Delete messages and revisions after a specified period
Let users set their own retention policies
For file retention, only two settings are currently available:
Retain all files, forever
Keep all files (including deleted files) forever
Delete files after a set number of days
Delete files (including deleted files) after a set number of days
Retain Everything, Forever
Retain Messages, Not Revisions
Set a Retention Schedule
Users Set Retention Schedule
Retaining all information is Slack’s default setting. This includes free accounts, where administrators have access to only 10,000 of the most recent messages—but, under this retention setting, Slack itself preserves them all.
If an administrator does not take action to change their retention policy, they could soon find themselves sitting upon a vast history of Slack conversations, reactions, integrations, and more—a potentially valuable resource, or a possibly costly liability, depending on your perspective.
Alternatively, if an administrator sets too liberal a retention schedule, or doesn't adjust the retention schedule in light of a legal hold or reasonably foreseeable litigation, spoliation could follow. Further, where individual team members control the retention of data in private channels and direct messages, one user’s messages could be eradicated at the end of every day, while another’s are preserved for all time.
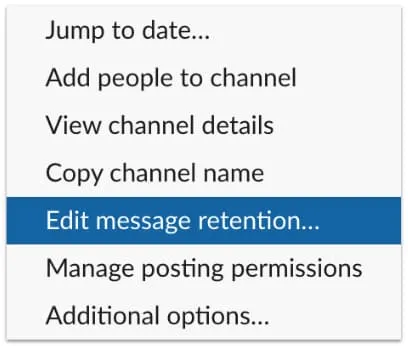
For all but free accounts, retention settings can be chosen for the workspace as a whole as well as for private channels and direct messages, allowing retention policies to be tailored to specific channels as one might to traditional email inboxes and custodians. But, again, those retention policies must be actively monitored to ensure that Slack data is not edited, destroyed, or otherwise spoliated.
How Slack Account Type Impacts Retention Settings
The ability to customize retention policies, as with most workspace administration features, depends on the type of Slack account used. Slack currently has four account types available:
- Free
- Pro
- Business+
- Enterprise Grid
These plans differ primarily in cost, storage size, and admin features. Plus and Enterprise plans, for example, can limit who can post in specific channels—other accounts cannot. Paid plans can set retention policies around private channels and direct messages; free plans cannot. Enterprise accounts, which span multiple workspaces, can apply retention settings across all of their Slack workspaces, a feature not available to any other account type.
Constantly Changing Data
Even when Slack data sizes are small, they can be hard to get one’s hands around. One reason for this is that conversations may take place in a muddle of formats—across public channels, private DMs, and comments on documents.
Another is that most Slack data is easily editable. An offensive photo can be deleted, a mistaken disclosure erased. A message that says one thing today can be edited to say another tomorrow.
Yet Slack creates a record of such alterations, often without users realizing it. If a Slack workspace retains editing and deletion information, those changes will be recorded in the metadata—and available in a review tool that knows how to process Slack data.
FREE
No Customization
PRO
Can set retention policies
BUSINESS+
Can set retention policies
ENTERPRISE
Access to Slack API
Exporting Data From Slack—or Collecting Directly from your eDiscovery Tool
For teams looking into Slack data, accessing everything Slack records can be difficult. Currently, Slack allows workspace owners and administrators in all plans to easily export data from public channels.
To export that available data, administrators can navigate to their workspace settings and select 'Import/Export Data.'
Administrators can export workspace data based on date ranges including:
- Data from the last 24 hours
- Data from the last 7 days
- Data from the last 30 days
- Data for the entire workspace history
- Data for specific date ranges
Once an export request is processed, the data can be downloaded in a .zip file with message history in JSON format and links to shared files. For single user’s channels and conversations, however, data can also be exported in TXT format.

What's Included in a Slack Export?
Every Slack plan has access to Slack's "Standard Export."
A standard export includes:
Messages shared in public channels
Links to files shared in public channels
Standard exports will not produce:
Messages and files shared in private channels
Messages and files shared in direct messages
Editing and deletion information
What's Included in a Slack Export?
To access all data, Slack requires any of the following:
Top-tier paid Business+ and Enterprise accounts
Valid legal process
Consent of members
A requirement or right under applicable laws
Finally, a Slack export will include available data from the entire workspace. Unless a user has an Enterprise account, it is not possible to limit exports to individual channels or users.
Slack in Litigation: Interpretation, Spoliation, Objections
Summary: Interpreting Slack ESI
There's no question that Slack is discoverable ESI—but it's not the same ESI most legal professionals are used to. Handling Slack data poses unique questions around interpretation, spoliation, and burden and proportionality objections.
- Our approach to custodians, preservation, review, and even spoliation is all based on discrete documents. But Slack data records streams of conversations, not discrete documents.
- Objections to the discovery of Slack data are common, but can be refuted with specific information on the cost and effort required for review and production.
- Communication in Slack is often informal and highly visual—think GIFs, emojis, images, etc.—leading to novel questions of interpretation.
Discovery Without Documents
There is no question that data created in Slack is electronically stored information that can be subject to discovery in litigation. There is also no question that Slack data can be essential to investigations, whether as part of litigation or not. Slack data is a potential treasure trove for legal professionals.
That’s where the certainty ends.
Today it is black letter law that computerized data is discoverable if relevant.” Anti-Monopoly, Inc. v. Hasbro, Inc., 94 Civ. 2120, 1995 WL 649934 (S.D.N.Y. 1995).
For modern legal teams, Slack presents a host of difficult, unanswered questions. How are legal professionals supposed to make sense of Slack’s more informal communication styles, such as the inclusion of emojis and gifs, or the ability to pin, react to, and star, messages? Who is a custodian on Slack? Who is responsible for data preservation when users can set their own retention policies? What is proportional discovery of Slack data and how does it align with users’ privacy interests?
Slack in Litigation: Starting with the Basics
Slack works more like an oral conversation than a document. Participants "speak" (or type) back and forth. Topics can float in an out. A conversation that began in one channel can be taken aside, for a more one-on-one discussion, or pop up again days later in an entirely other space. And all of it's recorded in multiple streams of information, rather than single, organized documents.
Yet most discovery and litigation processes are based on documents: emails, word processing files, spreadsheets. That means that old approaches need to be updated for more chat-based communications.
When dealing with Slack and similar data in discovery, begin by considering such questions as:
- What counts as a document? Is it a day of messaging? A week? Is it channel specific, participant specific, or does it encompass an entire workspace?
- What is responsive? It is it a single message? A line of text in a larger message? A message plus the surrounding 5 messages or the surrounding day's worth of messages?
These, of course, are all answerable questions. And, indeed, sophisticated parties will often come to a consensus on how to treat Slack data during the meet and confer process. But there is currently no industry standard on how to answer them.
Similarly, when determining a pre-litigation, information-governance approach to Slack data, or advising clients on theirs, consider questions such as:
- Is Slack communication a business record that needs to be preserved?
- Who will administer a Slack workspace?
- What retention policies are appropriate for your usage?
- What processes are needed to institute a legal hold on Slack data? Are they documented and defensible?
- How will you obtain and review Slack data when needed—either for litigation, compliance, or internal investigations.
Parties may obtain discovery regarding any non-privileged matter that is relevant to any party's claim or defense and proportional to the needs of the case...” - Federal Rule of Civil Procedure 26(b)(1)
Handling Objections to Slack Data
Given Slack’s novelty, and some of the difficulties associated with Slack data, it’s not uncommon to encounter objections that the reviewing and producing Slack data is disproportionate and burdensome. And it can be. Without the right tools, Slack data can present significant challenges around review and production. Exported directly from the Slack platform, for example, Slack data appears as virtually unreadable JSON code. But with discovery software that can parse and process that data, those burdens can be significantly reduced.
Often, simple facts are the most effective response to claims that the discovery of Slack data would be disproportional or burdensome. Consider the effort involved in obtaining Slack data for discovery. For all plans, the process of exporting public Slack data can be completed in minutes. For messages in private channels, direct messages, and editing logs, that data can be obtained directly under top-tier plans or after showing that the data is subject to discovery or other legal process.
Once obtained, the burden of reviewing Slack data for discovery will depend significantly on the review process and software used. In its native form, Slack data is a virtually incomprehensible mass of JSON code. Because Slack data is so rich with information, a single line of text can result in pages of JSON code.
And because Slack data is novel, many legacy eDiscovery platforms may not be able to handle it, and many vendors may charge a premium. But, with the right software, that data can be rendered and reviewed as easily as any other document type—and often at costs far below traditional approaches to discovery.
In Slack, such informality is much more common. Because Slack so closely resembles the informal chat rooms of the early internet, because it allows people to communicate rapidly, as they might in face-to-face conversations, because it creates a veneer of privacy and impermanence through its secret channels and editable messages, and because it allows for media-saturated discussions, conversations in Slack often disregard typical office decorum.
This, in turn, raises interpretive difficulties. How is a legal professional, a judge, or a jury, supposed to make sense of a heart emoji in reaction to a Slack message, a ̄\_(ツ)_/ ̄ in response to an inquiry, or that .GIF of Betty White?
To complicate things even more, Slack allows users to create their own emojis by uploading a small image. In addition to the Unicode-regulated world of peach emojis, dancing ladies, and clap-backs, users can add a whole universe of emojis, from Star Wars images to their coworkers’ faces, meant to convey... what exactly? That’s the problem, isn’t it?
Of course, these aren’t issues unique to Slack. Legal professionals working on the forefront of internet communications have been struggling with these same interpretive issues for a while now. As Santa Clara University School of Law Professor Eric Goldman has noted, the profession is currently struggling with at least nine specific “emoji-related interpretive challenges,” from how to report them in court opinions, to how to convey them to a jury, to how to search from them during discovery. But Slack brings these issues increasingly to the forefront by bringing them from the margins and into the center of corporate communication.
Communication in Slack: The Medium Is The Message
When it comes to business communication, Slack is unique. Let’s start with the way communication occurs in Slack, not just its channels, integrations, and messages, but its tone and idiosyncrasies. In few corporate meetings would you respond to a colleague with a simple thumbs down emoji.
You probably would not communicate with a coworker through a .GIF of Betty White doing a shoulder shimmy.


Slack Spoliation: Just a Click Away?
Interpretive issues are not the only challenges Slack creates. Take, for example, the traditional idea of the custodian. The Electronic Discovery Reference Model’s glossary defines “data custodian” as a person “having administrative control of a document or electronic file”. It identifies the owner of an email account as the prototypical example.
With Slack data, determining custodians is a bit more complicated. Individuals with administrative access to a workspace have the ability to export public information. But they may not have easy access to private channels, direct messages, and changelogs. Individual users, who can see their own private communications, cannot export that data without administrative access. And while Slack makes it difficult for one custodian to truly control data, it creates the sense of control through private channels and editable, deletable messages.
The control Slack allows over an individual’s messages also creates significant risks of spoliation. Under Federal Rule of Civil Procedure 37(e), as with most state analogues, the loss or destruction of electronically stored information that should have been preserved in the anticipation or conduction of litigation can result in significant sanctions. Where there is a showing that the spoliating party acted with the intent to deprive another of evidence, those sanctions can be case-dispositive.
Rule 37. Failure to Make Disclosures or to Cooperate in Discovery; Sanctions
e) Failure to Preserve Electronically Stored Information. If electronically stored information that should have been preserved in the anticipation or conduct of litigation is lost because a party failed to take reasonable steps to preserve it, and it cannot be restored or replaced through additional discovery, the court:
- upon finding prejudice to another party from loss of the information, may order measures no greater than necessary to cure the prejudice; or
- only upon finding that the party acted with the intent to deprive another party of the information’s use in the litigation may:
- (A) presume that the lost information was unfavorable to the party
- instruct the jury that it may or must presume the information was unfavorable to the party; or
- dismiss the action or enter a default judgment.
IMAGES & GIFS
Pose interpretive challenges
SHARED FILES & INTEGRATIONS
Centralize data in Slack
EMOJIS & EMOTICONS
Create a unique vocabulary
EDITS & DELETION
Can risk spoliation
It’s not difficult to image, for example, a Slack user deleting a host of messages in an attempt to remove potential evidence. Consider, for instance, a manager who has been accused of creating a hostile work environment. Before a lawsuit is filed, before even an investigation has been launched by H.R., she deletes several Slack messages that could be “taken the wrong way.” She edits a few. In her mind, those are simply gone. After all, there is no way to see original messages once they’re edited in Slack. Only an (edited) note marks the change. And when messages are deleted altogether, they seem, in the user’s eyes, to fully disappear.
Yet, unless the underlying workspace data is destroyed, many of these attempts at spoliation will remain just attempts. With the proper retention settings, Slack records all messages, edits, and deletions. With the right eDiscovery software, finding this hidden information is simple.
Before legal professionals can tackle these issues, though, they have to deal with the most pressing one:
How do you even make sense of Slack data?
Handling Slack Data in Discovery and Investigations
Summary: Slack eDiscovery Tools
Slack data can be incredibly valuable, whether in litigation, compliance, or internal investigations. But without the proper tools, Slack data is virtually indecipherable.
- Slack data exports as JSON files, which can be difficult or impossible to review.
- The proper discovery tools can integrate with Slack for instant collection, and render it into an easy-to-review format, surfacing valuable metadata, such as editing and deletion logs.
- You don't need to pay exorbitant prices to handle Slack data; the right discovery platform will treat it just like any other project and even have specific capabilities for managing Slack data more efficiently.
Making Sense of Slack Data
When you, or your client, exports data or collects chat data directly from a Slack workspace, it will come as several—potentially thousands—of JSON files, for Javascript Object Notation. And JSON data isn't something you can review like an email of PDF. Here for example, is what a simple record of a user joining a channel looks like when exported directly from Slack:
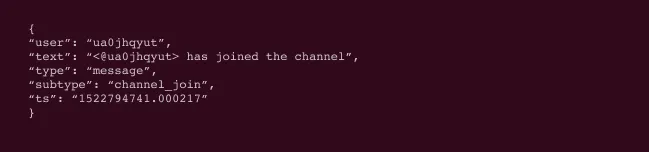
"Your engineers will know what to do with these," Slack explains.
But how many clients, and how many law firms, have engineers at all, let alone the engineering bandwidth to create a platform that can process and interpret Slack data? And when it comes to Slack review, very few legal tools are designed to handle Slack data.
As Slack data becomes increasingly rich and complex—full of information message type, edit logs, reactions and more—it becomes even more difficult to handle.
Take comments on a shared file, for example. In Slack, this would appear as a simple message under the file, just a few lines long. When exported from Slack, here's what that those comments look like when exported in JSON format:
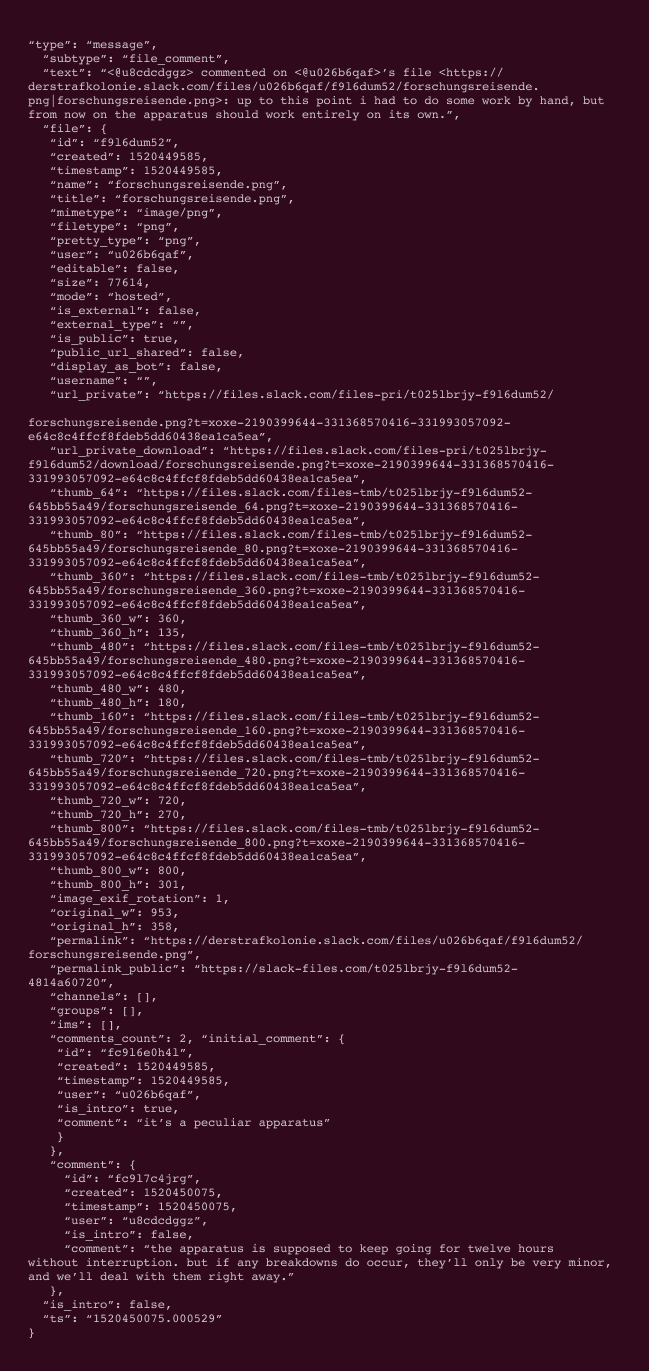
You certainly can't review these files on their own. And you can’t toss this into just any discovery software and expect it to be reviewable.
How To Review Exported Slack Data: Processing Slack Data
To make sense of data exported from Slack, you need a platform that is designed to process Slack's JSON data and render it in a form at that is easy to review. That doesn't mean just extracting text messages and leaving the rest behind. There is valuable information in Slack's deluge of JSON code, after all!
Your platform should also make that information available—particularly information such as user names, time and date stamps, file types, comments, and edit or deletion records—and include Slack-specific filters so that you can sort conversations by the most relevant criteria for you like participants, channels, and even reactions.
Discovery software like Logikcull can do just that, in a platform that is powerfully simple. In Logikcull, handling Slack data is as easy as sync or upload, search, download.

With Logikcull, you can either pull the data directly from Slack through its direct Slack integration, or upload data previously exported from Slack.
As soon as your chat data is ingested into the platform, it goes through 3,000 automated processing steps: text is rendered and indexed for the most accurate eDiscovery search available, metadata is extracted and preserved to protect against spoliation, quality control tags are applied, and much more.
Slack metadata is instantly turned into filters like conversation participants, channel, sender, deleted and edited messages, and even reactions. You can leverage these filters to cull through chat data and quickly surface the important information.
Slack conversations are also rendered instantly searchable, whether you’re looking for simple text search for keywords or constructing an advanced Power Search based on metadata fields. When it comes time to review Slack documents, Logikcull creates a representation of Slack data similar to how it is displayed in the Slack user interface.
See it in action below:
Tips For Reviewing Slack Data
Once exported from Slack and processed for review in a platform like Logikcull, many of the same discovery best practices that apply to any document review can be employed on Slack data, and you can also leverage features tailor made to handle chat data.
You can create custom tags, test and refine search terms, perhaps through a bulk keyword search, and you can batch out chat data to to your team for review.
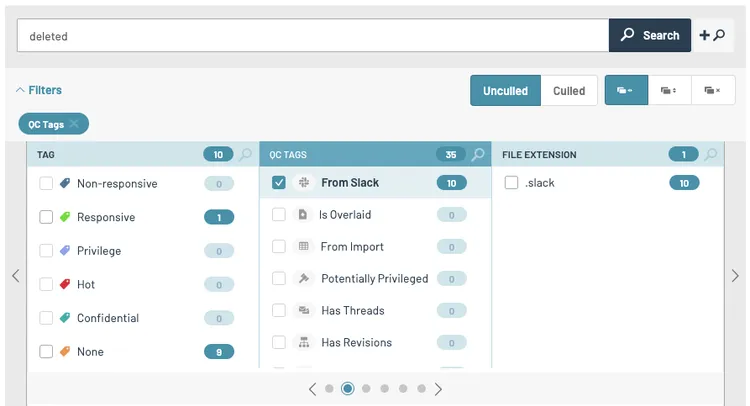
You will also want to be able to quickly identify Slack documents from the rest of your document corpus. In Logikcull, when Slack chats are uploaded, each Slack document is marked with a Slack QC tag. Additionally, you’ll see several chat-specific filters, such as “participants,” “channel,” or “reactions,” which were created with Slack data in mind. These allow you to surface important conversations quickly.
As Slack creates a near-constant stream of communication, it's likely that the vast majority of it will be unnecessary junk. Using powerful culling and search technology, reviewers can easily cull through the vast amounts of data produced by Slack to quickly find and tag the most important information—and cut out the rest.
When review is completed, those Slack documents can be downloaded and produced to others through a secure, permission-based link, allowing you to make sure that your data stays protected throughout your discovery process.
Finding Deleted or Edited Messages in Slack Metadata
Remember that Slack records more data than the user interface displays. Thus, when a message is deleted in Slack, it will simply disappear—at least, that's what it appears like to users. Similarly, when a message is edited, only the final, altered text is displayed, alongside the parenthetical "(edited)." But, with the proper Slack retention settings, that information can be logged, retained, and surfaced on review.
If a message is deleted, Logikcull displays the deleted information and the time of its attempted destruction. If it is edited, Logikcull shows the original message, the altered version, and the time of the change. That way, review teams can bring clarity to otherwise opaque information—information that could be key to the discovery and investigation processes.
IMAGES & GIFS
Pose interpretive challenges
SHARED FILES & INTEGRATIONS
Centralize data in Slack
EMOJIS & EMOTICONS
Create a unique vocabulary
EDITS & DELETION
Can risk spoliation
Taking Control of Slack Data
Though Slack presents significant challenges when it comes to litigation and investigations, with the right tools, legal professionals truly can treat Slack as a “searchable log of all conversation and knowledge.”
The first step is to integrate Slack into your regular discovery and investigations process. That means discussing Slack retention and information governance policies with clients. It means adding Slack data to your preservation letters, requests for production, and custodian interviews.
It means looking for indications that Slack might be at issue in a matter, such as the email notifications many users get when receiving a mention or direct message. (Search for the keyword “Slack” or the email address “no-reply@slack.com.”)
Most importantly, it means finding a platform that can help you make sense of Slack, one that supports robust a direct integration with Slack for immediate collection, plus dedicated features for chat dpata culling, document review, tagging, and collaboration, without requiring the intervention of a highly technical IT team—and doesn't charge extraordinary prices for it.
After all, if your Slack discovery solution doesn’t provide comprehensive collection, review, tagging, and collaboration features, then it’s not giving you the tools you need to handle Slack data.
If your Slack discovery process requires you to bring on computer technicians or to pay for a six-figure software setup, then it’s only adding to the problems Slack data creates; it’s not solving them.
That's why Logikcull lets you turn Slack data from a burden into an opportunity, making Slack discovery and investigations simple, secure, and straight-forward thanks to its Slack direct integration and chat filters.
It's the closest thing legal teams can get to a searchable log of all content and knowledge.
The Ultimate Guide to eDiscovery
Want to accelerate internal investigations? Let's chat.
Our team of product specialists will show you how to make Logikcull work for your specific needs and help you save thousands in discovery and internal investigations.